今天來完成最重要的步驟,
除了昨天看過的土銀-白河 對 所羅門(2359)個股 單一券商歷史明細
https://fubon-ebrokerdj.fbs.com.tw/z/zc/zco/zco0/zco0.djhtm?A=2359&BHID=1030&b=0031003000330043&C=1&D=2024-5-13&E=2024-5-16&ver=V3
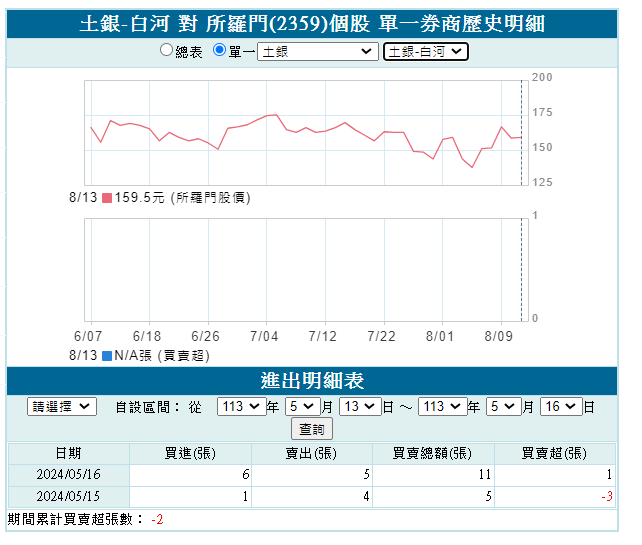
右鍵研究了它的網頁原始碼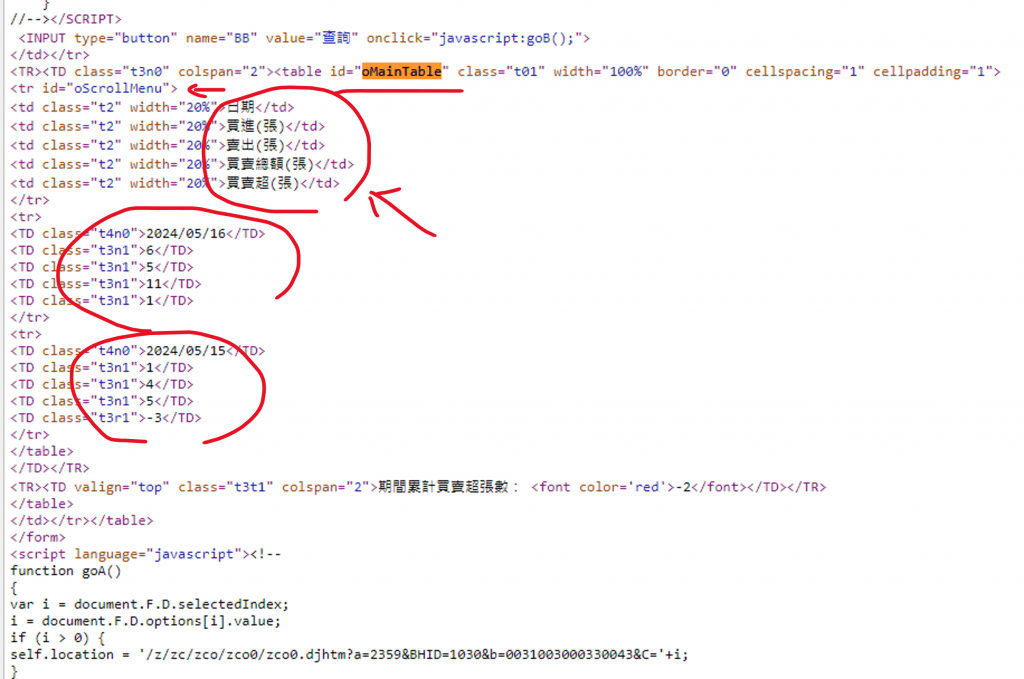
引入需要的套件庫
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
# 設定瀏覽器選項
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 啟用無頭模式
options.add_argument('--disable-gpu') # 避免某些環境下的bug
current_path = os.path.abspath(os.getcwd())
# The path of ChromeDriver
chromeDriver = current_path + r'/chromedriver.exe'
driver = webdriver.Chrome()
# 啟動瀏覽器
#driver = webdriver.Chrome(options=options)
driver.get('https://fubon-ebrokerdj.fbs.com.tw/z/zc/zco/zco0/zco0.djhtm?A=2359&BHID=1030&b=0031003000330043&C=1&D=2024-5-13&E=2024-5-16&ver=V3')
最後用try寫,包起來
# 等待表格元素出現
try:
table_element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "oMainTable"))
)
# 取得頁面內容
page_source = driver.page_source
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(page_source, 'html.parser')
table = soup.find('table', {'id': 'oMainTable'})
# 檢查表格是否存在
if table is None:
print("找不到目標表格")
else:
# 提取表格中的資料
data = []
for row in table.find_all('tr')[1:]: # 跳過表頭
cols = row.find_all('td')
if len(cols) == 5:
date = cols[0].text.strip() # 日期
buy = cols[1].text.strip() # 買張
sell = cols[2].text.strip() # 賣張
total = cols[3].text.strip() # 買賣總額
net = cols[4].text.strip() # 買賣超
data.append([date, buy, sell, total, net])
# 輸出提取的資料
for item in data:
print(item)
finally:
driver.quit()
['2024/05/16', '6', '5', '11', '1']
['2024/05/15', '1', '4', '5', '-3']
爬取成功,感動QQ
再來最好玩的地方來了~
預防沒有裝需要的套件工具,這邊有pip install 套餐
pip install pandas openpyxl selenium beautifulsoup4 webdriver-manager
# 如果這是 土銀-白河,券商代碼:103C
https://fubon-ebrokerdj.fbs.com.tw/z/zc/zco/zco0/zco0.djhtm?A=2359&BHID=1030&b=0031003000330043&C=1&D=2024-5-13&E=2024-5-16&ver=V3
# 換成 土銀-士林,券商代碼:1039
https://fubon-ebrokerdj.fbs.com.tw/z/zc/zco/zco0/zco0.djhtm?a=2359&BHID=1030&b=1039
重點在b=.... 後面接不同券商代碼,就是不同券商的資料!
PLUS_lat_lng_address.xlsx,券商代碼這個欄位作為索引還記得 DAY13 含金量滿滿的文章? Step(1/3):關鍵分點籌碼爬蟲,之前拿到的券商地點,要怎麼處理?
最後拿到的PLUS_lat_lng_address.xlsx ,URL後面就可以接上裡面不同的券商代碼,
這樣就可以爬到所有券商分點這段期間對這檔股票的所有籌碼資料!!!
引入需要的套件庫
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
from webdriver_manager.chrome import ChromeDriverManager
import time
# 讀取 Excel 資料
excel_file = 'PLUS_lat_lng_address.xlsx'
df = pd.read_excel(excel_file)
# 設定瀏覽器選項
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 啟用無頭模式
options.add_argument('--disable-gpu') # 避免某些環境下的bug
# 啟動瀏覽器
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
設定要爬取的股票代號和日期範圍
stock_code = '2359'
start_date = '2024-5-13'
end_date = '2024-5-16'
把上面那段程式碼,稍微改裝一下
# 初始化結果列表
results = []
# 用券商代碼的欄位作為索引,for迴圈跑過每個券商代碼
for index, row in df.iterrows():
broker_code = row['券商代碼']
url = f"https://fubon-ebrokerdj.fbs.com.tw/z/zc/zco/zco0/zco0.djhtm?a={stock_code}&BHID=1030&b={broker_code}&C=1&D={start_date}&E={end_date}&ver=V3"
driver.get(url)
try:
# 等待表格元素出現
table_element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "oMainTable"))
)
# 取得頁面內容
page_source = driver.page_source
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(page_source, 'html.parser')
table = soup.find('table', {'id': 'oMainTable'})
# 檢查表格是否存在
if table is not None:
# 提取表格中的資料
for row in table.find_all('tr')[1:]: # 跳過表頭
cols = row.find_all('td')
if len(cols) == 5:
date = cols[0].text.strip()
buy = cols[1].text.strip()
sell = cols[2].text.strip()
total = cols[3].text.strip()
net = cols[4].text.strip()
results.append([broker_code, date, buy, sell, total, net])
except Exception as e:
print(f"Error processing broker code {broker_code}: {e}")
time.sleep(1) # 短暫等待,避免頻繁請求
# 爬完,關閉瀏覽器
driver.quit()
最後把結果存起來! 不然就要跑辛酸的了(一次也是要跑很久的,還要小心會中斷)
建議在跑的時候就放著觀賞,不要用電腦去做其他事,不然它會像實驗室裡面的細菌一樣要死不活(?
# 將結果保存到新的Excel檔案
results_df = pd.DataFrame(results, columns=['券商代碼', '日期', '買進', '賣出', '總數', '淨額'])
results_df.to_excel('broker_trade_data.xlsx', index=False)
(看著它自己在跑,真的很療癒,爬蟲的快樂)
最後拿到的broker_trade_data.xlsx就會長成下面這樣,很多很多資料~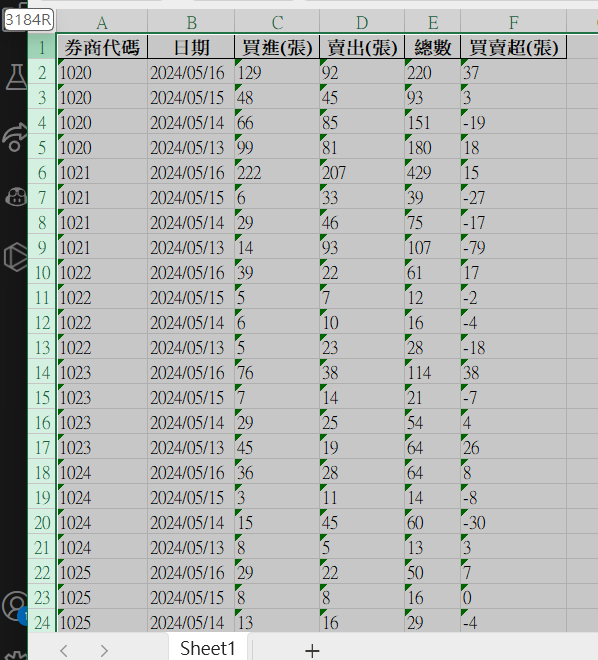
明天禮拜六見! (Meeting完獲得短暫的快樂 :D)
每日記錄:
加權指數:收在22349.33點,上漲454.16點。
昨晚美國 7 月零售銷售大幅超出預期(預期0.2%,實值1.0%),初領失業救濟金的人數也下降,美股直接大噴出。台股也跟著漲,但是量能不大,還在4千初億,外資系統單直接一個大回補。
應該很多人從賠錢變成開始賺錢了~(只要上禮拜沒有砍在阿呆谷)
收集完資料,就可以開始把資料轉置、處理一下,接著建立模型,訓練模型!
您好,非常感謝你的文章,很受用!
想請教你要如何修改成取得"期間累積買賣超張數"的數值呢
而且我發現他有兩種寫法 
<td valign="top" class="t3t1" colspan="2">期間累計買賣超張數: 0</td>
<td valign="top" class="t3t1" colspan="2">期間累計買賣超張數: <font color="red">-2</font></td>

